- 产品详情
- 产品参数
- 产品评论
 | ——SubtypeGSEA代码 |
GSEA全名为Gene SetEnrichment Analysis(基因集富集分析)。用以分析特定基因集(如关注的GO条目或KEGGPathway)在两个生物学状态(如癌症与对照,高龄与低龄)中是否存在差异。能够研究基因变化的生物学意义。
SubtypeGSEA是在GSEA的基础上对不同亚型样本中重要通路的富集情况进行组间比较,能直观比较不同亚型中相同通路富集情况。
基本原理
GSEA主要分为基因集进行排序、计算富集分数(Enrichment Score,ES)、估计富集分数的显著性水平并进行多重假设检验三个步骤。
第一步对输入的所有基因集L进行排序,通常来说初始输入的基因数据为表达矩阵,排序的过程相当于特定两组中(case-control、upper-lower等等)基因差异表达分析的过程。根据所有基因在两组样本的差异度量不同(共有六种差异度量,默认是signal 2 noise,GSEA官网有提供公式,也可以选择较为普遍的foldchange),对基因进行排序,并且Z-score标准化。
第二步是GSEA的核心步骤,通过分析预先定义基因集S在第一步获得的基因序列上的分布计算富集指数Enrichment Score,并绘制分布趋势图Enrichment plot。每个基因在基因集S的EnrichmentScore取决于这个基因是否属于基因集S及其差异度量(如foldchange)。差异度量越大基因的EnrichmentScore权重越大,如果基因在基因集S中则Enrichment Score取正,反则取负。将基因集L在基因集S里的所有基因的Enrichment Score一个个加起来,就是Enrichment plot上的Enrichment Score趋势,直到Enrichment Score达到最大值,就是基因集S最终的EnrichmentScore。
第三步是为了检验第二部获得结果的统计学意义,对Enrichment Score进行标准化,计算标准化Enrichment Score(NES)。并计算显著性水平(NOMp-val)和矫正多重假设检验显著性水平(FDR q-val)。
SubtypeGSEA则进一步整合不同亚型样本富集到的关键基因集S的GSEA富集分数,绘制热图进行比较性展示。
数据要求
1、通常为表达谱芯片或测序数据(已经过预处理),也可以是其他形式可排序的基因数据。
2、具有已知生物学意义(GO、Pathway、癌症特征基因集等)的基因集。
3、样本对应亚型数据
下游分析
得到GSEA结果之后的分析有:
1. 不同亚型生存分析
2.不同亚型GSVA分析和量化的差异比较
图形示例:
1、三个亚型中上调Top基因集的富集度比较
图注:
图中热横坐标的3列对应3个亚型(分组),最左侧色条的背景色对应3个亚组(分组)富集的上调前10基因集。
2、三个亚型中下调Top基因集的富集度比较
图注:
图中热横坐标的3列对应3个亚型(分组),最左侧色条的背景色对应3个亚组(分组)富集的下调前10基因集。
应用示例:
文献1:Gene expression profiling of 1200 pancreatic ductal adenocarcinoma reveals novelsubtypes.(于2018年5月发表在BMC cancer,影响因子2.933)
基于1200个胰腺导管腺癌的基因表达数据划分新的分子亚型
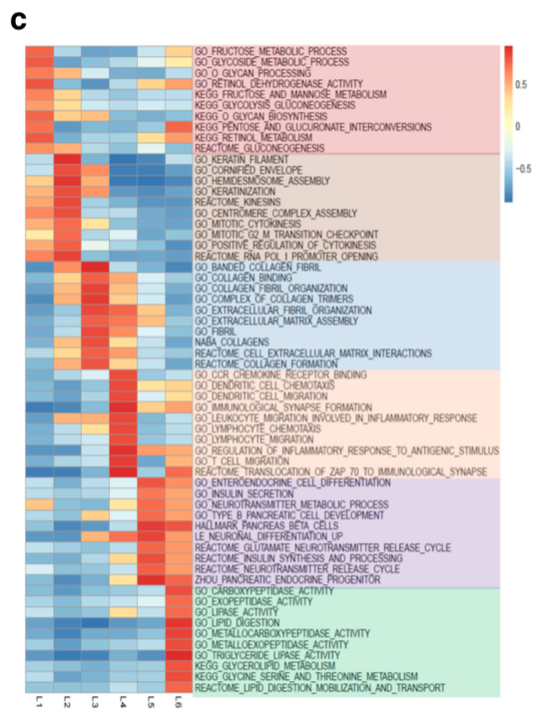
为了分析胰腺导管腺癌的异质性,作者分析了1200个患者的基因表达数据,并最终将患者分为6种亚型。文中使用SubtypeGSEA比较了这6种亚型患者表达数据GSEA结果的差异。
文献2:Head and neckcancer subtypes with biological and clinical relevance: Meta-analysis ofgene-expression data(于2015年4月发表于Oncotarget.,影响因子5.008)
头颈瘤中根据生物学意义和临床特性划分亚型:基因表达数据的meta分析
为了更好的对头颈瘤患者分层并进行针对性治疗,作者基于大量头颈瘤样本进行meta分析,并划分出与预后相关的六个亚型。文中绘制SubtypeGSEA展示了不同亚型中富集分子途径和癌症特征的差异。
;){kind=link}